Mysql查询优化
查询执行流程
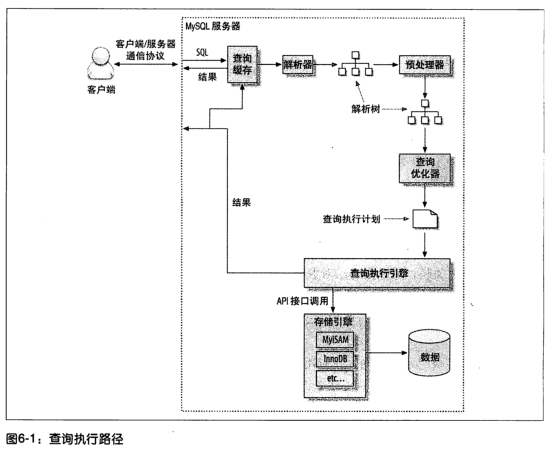
如图所示,mysql的查询一般分为如下步骤:
- 客服端发送一条查询给服务器
- 服务器先检查查询缓存,如果命中缓存,则立刻返回存储在缓存中的结果。否则进入下一个阶段。
- 服务器端进行SQL解析、预处理,在由优化器生成对应的执行计划。
- MySQL根据优化器生成的执行计划,调用存储引擎的API来执行查询
- 将结果返回给客户端
注意点
字段
- 尽量使用TINYINT、SMALLINT、MEDIUM_INT作为整数类型而非INT,如果非负则加上UNSIGNED
- VARCHAR的长度只分配真正需要的空间
- 使用枚举或整数代替字符串类型
- 尽量使用TIMESTAMP而非DATETIME,
- 单表不要有太多字段,建议在20以内
- 避免使用NULL字段,很难查询优化且占用额外索引空间
- 用整型来存IP
索引
- 索引并不是越多越好,要根据查询有针对性的创建,考虑在WHERE和ORDER BY命令上涉及的列建立索引,可根据EXPLAIN来查看是否用了索引还是全表扫描
- 应尽量避免在WHERE子句中对字段进行NULL值判断,否则将导致引擎放弃使用索引而进行全表扫描
- 值分布很稀少的字段不适合建索引,例如"性别"这种只有两三个值的字段
- 字符字段最好不要做主键
- 不用外键,由程序保证约束
- 尽量不用UNIQUE,由程序保证约束
- 使用多列索引时主意顺序和查询条件保持一致,同时删除不必要的单列索引
SQL
- 可通过开启慢查询日志来找出较慢的SQL
- 不做列运算:SELECT id WHERE age + 1 = 10,任何对列的操作都将导致表扫描,它包括数据库教程函数、计算表达式等等,查询时要尽可能将操作移至等号右边
- sql语句尽可能简单:一条sql只能在一个cpu运算;大语句拆小语句,减少锁时间;一条大sql可以堵死整个库
- 不用SELECT *
- OR改写成IN:OR的效率是n级别,IN的效率是log(n)级别,in的个数建议控制在200以内
- 不用函数和触发器,在应用程序实现
- 避免%xxx式查询
- 少用JOIN
- 使用同类型进行比较,比如用'123'和'123'比,123和123比
- 尽量避免在WHERE子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描
- 对于连续数值,使用BETWEEN不用IN:SELECT id FROM t WHERE num BETWEEN 1 AND 5
- 列表数据不要拿全表,要使用LIMIT来分页,每页数量也不要太大