Spark在Standalone运行架构中的运行流程
Standalone
Standalone模式是Spark实现的资源调度框架,其主要的节点有Client节点、Master节点和Worker节点。其中Driver既可以运行在Master节点上中, 也可以运行在本地Client端。当用spark-shell交互式工具提交Spark的Job时,Driver在Master节点上运行; 当使用spark-submit工具提交Job或者在Eclips、IDEA等开发平台上使用”new SparkConf().setMaster(“spark://master:7077”)”方式运行Spark任务时, Driver是运行在本地Client端上的。
具体流程
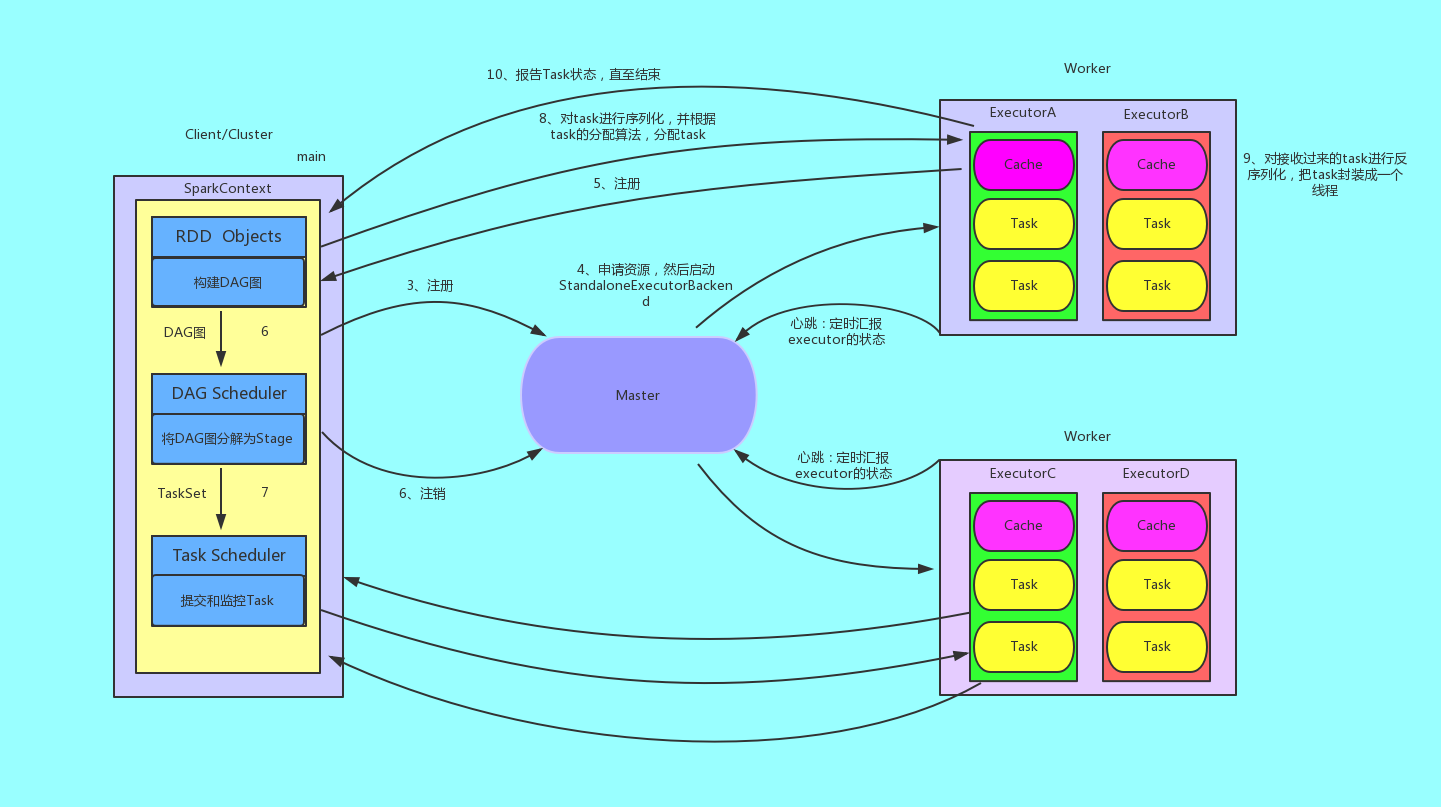
- 我们提交一个任务,任务就叫Application
- 初始化程序的入口SparkContext
- 初始化DAG Scheduler
- 初始化Task Scheduler
- Task Scheduler向master去进行注册并申请资源(CPU Core和Memory)
- Master根据SparkContext的资源申请要求和Worker心跳周期内报告的信息决定在哪个Worker上分配资源,然后在该Worker上获取资源,然后启动StandaloneExecutorBackend;顺便初始化好了一个线程池
- StandaloneExecutorBackend向Driver(SparkContext)注册,这样Driver就知道哪些Executor为他进行服务了。 到这个时候其实我们的初始化过程基本完成了,我们开始执行transform、ation的代码,但是代码并不会真正的运行,直到我们遇到一个action操作。先生产一个job任务,进行stage的划分。
- SparkContext将Applicaiton代码发送给StandaloneExecutorBackend;并且SparkContext解析Applicaiton代码,构建DAG图,并提交给DAG Scheduler分解成Stage(当碰到Action操作时,就会催生Job;每个Job中含有1个或多个Stage,Stage一般在获取外部数据和shuffle之前产生)。
- 将Stage(或者称为TaskSet)提交给Task Scheduler。Task Scheduler负责将Task分配到相应的Worker,最后提交给StandaloneExecutorBackend执行;
- 对task进行序列化,并根据task的分配算法,分配task
- 对接收过来的task进行反序列化,把task封装成一个线程
- 开始执行Task,并向SparkContext报告,直至Task完成。
- 资源注销